
Тип МП
корпуса
Таблица 3.6
| Вершина графа | x1 | x2 | х3 | x4 | x5 | х6 | x7 | x8 | х9 | |||||||||||||||
| Описание выполняемой операции | ЗГ | ЗГ | УМН | ЗП | ЗГ | УМН | ЗП | ЗГ | УМН | |||||||||||||||
| Время выполнения КР1802 | 0,45 0,45 | 0,15 | 0,45 | 0,45 | 0,15 | 0,45 | 0,45 | 0,15 | ||||||||||||||||
| операции, мкс К1800 | 0,09 0.09 | 0,6 | 0,03 | 0,09 | 0,6 | 0,03 | 0,09 | 0,6 | ||||||||||||||||
| КМ1804 | 0,3 0,3 | 1,7 | 0,1 | 0,3 | 1,7 | 0,1 | 0,3 | 1.7 | ||||||||||||||||
| Вершины-последователи | х3, хе ха, х12 | x4 , x10 | — | Хд, х9 | х7, х13 | — | Х9, Х12 | X10 | ||||||||||||||||
| X10 | X11 | X12 | Х13 | X14 | X15 | X16 | X17 | Х18 | X19 | X20 | X21 | X22 | X23 | X24 | ||||||||||
| ВЧТ | 1 ЗП | УМН | СЛ | ЗП | ЗГ | СЛ | 1 ЗП | | ВЧТ | ЗП | ЗГ | СЛ | ЗП | ВЧТ | ЗП | ||||||||||
| 0,15 | 0,45 | 0Л5 | 0,15 | 0,45 | о | 0,15 | 0,15 | 0,15 | 0,15 | 0,45 | 0,15 | 0,15 | 0,15 | 0,15 | ||||||||||
| 0,03 | 0,03 | 0,6 | 0,03 | 0,03 | 0,09 | 0,03 | 0,03 | 0,03 | 0,03 | 0,09 | 0,03 | 0,03 | 0,03 | 0,03 | ||||||||||
| 0,1 | 0.1 | 1,7 | 0,1 | 0,1 | 0,3 | 0.1 | 0.1 | 0,1 | 0,1 | 0,3 | 0,1 | 0,1 | 0,1 | 0,1 | ||||||||||
| Х11,x16, x18 | — | X13 | X14, X21, X22 | — | Х16, X18 | X17 | — | X19 | — | X2l, X23 | X22 | — | X24 | |||||||||||
Потери БО
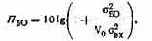
где б2БО — среднее квадратическое значение вычислений БО; б2вх = б2ш+б2ацп, При выборе цены младшего разряда АЦП ДАцп=бш, допуская, что ошибки округления равномерно распределены по амплитуде в пределах младшего разряда и имеют дисперсию [2], б2АцП=бш2/12, получим б2Вх= 1,08 бш2.
Поскольку бш и ПБО заданы, из (3.12) можно определить аБО и в соответствии с пп. 1 — 4 алгоритма найти l.
Решая уравнение (3.12) относительно сгБО, получим: аБО»28,7 мВ. Так как динамический диапазон d=lO lg/(UMaKc/б2BX), то
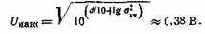
Разрядность ячеек входного ОЗУ
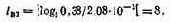
Разрядность МП, обеспечивающая шумовые потери на вычислении БО массива) из 128 входных отсчетов, равна
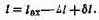
Принимаем о-и = сгБО; тогда Дl=5.
Как следует из (2.2), вычисление двухточечного БПФ включает четыре умножения и шесть сложений действительных чисел. При выполнении БПФ массива из N входных отсчетов необходимо выполнить N/2-log2N БО. С учетом этого, длина цепочки последовательных операций с округлениями г|з = 1792~ Тогда
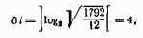
l=8 бит.
Итак, для обеспечения потерь на вычисление БО не более 4 дБ разрядность МП должна быть равна 8. Однако чаще всего разрядность МП обработки сигналов определяет не допустимый уровень потерь, а требование отсутствия аномальных погрешностей, вызванных переполнением разрядной сетки МП. Во избежание переполнений используются различные методы масштабирования результатов вычислений [30]. Каждый метод требует затрат процессорного времени на выполнение операций масштабирования, которых в условиях жестких временных ограничений может не оказаться. Тогда заведомо увеличивают разрядность МП с тем расчетом, чтобы гарантировать отсутствие переполнения на всех этапах вычислений. При этом, конечно, увеличиваются аппаратные затраты.
С учетом изложенного разрядность МП ltm>l + L + знаковый разряд, где L = log2N — старшие разряды кода входных данных, добавляемые для предотвращения переполнений на всех этапах вычислений Выберем lМП = 16
При коррекции времени выполнения операций с учетом разрядности необходимо учитывать следующее: в табл. 3.5 длительность программной реализации операции умножения соответствует 16-разрядным числам. Кроме того, при выполнении арифметических операций используются микросхемы ускоренного переноса К500ИП179 и КМ1804ВР1, которые вносят незначительную задержку распространения сигнала переноса (2 и 15 не соответственно). С учетом этого в табл. 3.6 приведены времена выполнения шагов программы БО.
Вычисление БО на МПК КР1802 может быть реализовано с использованием параллельного умножителя 16x16 типа КР1802ВР5. Умножитель обменивается информацией с МП БИС КР1802ВС1 по магистрали данных. При этом увеличивается время записи произведения, так как пересылка между МП БИС и умножителем эквивалентна пересылке Рг — П.
Алгоритм БО БПФ представляет собой цепочку последовательных операций, значит, TПр равно сумме времен выполнения отдельных его шагов: Tпp1 = 6,6 мкс, TПр2=3,36 мкc, Tпр3= 10 мкс. Микропроцессоры, приведенные в табл. 3.4, не обеспечивают вычисление БО в реальном времени. Для повышения быстродействия вычисления БО необходимо распараллелить ее алгоритм. Для этого в соответствии с п. 12 приведенного выше алгоритма и по данным табл. 3.6 строим матрицу данных (рис. 3.7). Из этой матрицы можно определить подпрограммы, допускающие параллельные вычисления.
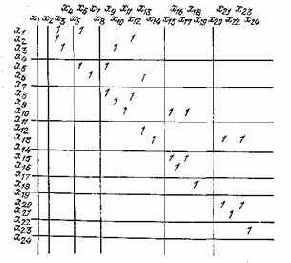
Рис. 3.7. Матрица данных алгоритма базовой операции быстрого преобразования Фурье
Последовательность выполнения подпрограмм по тактам представлена на рис. 3.8. При распараллеливании алгоритма БО БПФ он выполняется за пять тактов. Однако время выполнения БО может быть доведено до одного такта при использовании «конвейерной» структуры вычислений. Принципы построения таких вычислителей рассмотрены в [33, 39]. Суть «конвейерной» организации вычислений заключается в том, что для реализации некоторой программы используются N МП, каждый из которых выполняет только часть программы.
Промежуточный результат вычислений 1-го МП передается i+1-му, а i- й МП принимает новые исходные данные от I — 1 МП и повторяет вычисление своей подпрограммы. Программа должна быть распределена между МП таким образом, чтобы обеспечивалась максимальная загрузка каждого МП. Это возможно лишь в случае равенства времен выполнения своих подпрограмм всеми МП, включенными в «конвейер». В любом другом случае длительность одного такта работы «конвейера» будет определяться самым медленным МП цепочки.
При конвейерном вычислении БО на первом такте вычисляются вершины хи х% х5, xs, на втором х3, х6, хд, хХч и т. д. Через пять тактов на выходе МП появится первый результат, последующие результаты будут появляться через каждый такт.
Анализ времен выполнения отдельных операций показывает, что при реализации БО на МПК БИС серий К1800 и КМ 1804 длительность умножения значительно больше длительности выполнения других операций. Поэтому в данном случае целесообразно распараллелить алгоритм БО, например при использовании двух МП K1800BG1 на первом могут быть выполнены подпрограммы I, II, III, VI, VII; на втором IV, V, VIII и IX (рис. 3.8). С учетом дополнительных операций пересылок время выполнения БО будет примерно равно 1,86 мкс, что удовлетворяет временному ограничению. Проводя формальный анализ данных табл. 3.5 и 3.6, а также матрицы данных (рис. 3.7 и 3.8), можно генерировать различные структурные варианты построения МП БО. Некоторые из них показаны на рис. 3.9.
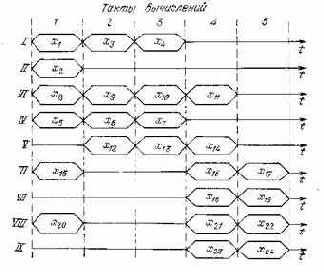
Рис. 3.8. Временная диаграмма вычисления базовой операции быстрого преобразования Фурье (I — IX — подпрограммы)
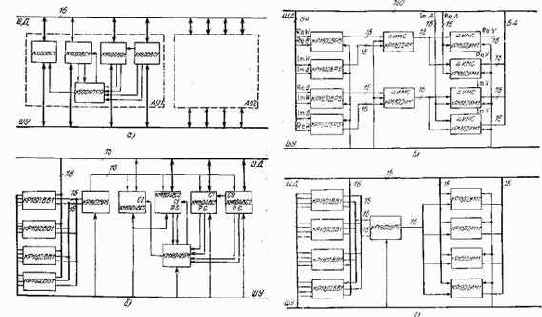
Рис. 3.9. Структурные схемы микропроцессоров базовых операций на МПК К1800 (а), КР1802 и КМ1804 (б) с распараллеливанием вычислений (в) и без распараллеливания вычислений (г)
Микропроцессор, представленный на рис. 3.9,6, использует «конвейерную» организацию вычислений. В соответствии с временной диаграммой на рис. 3.8 на первом этапе осуществляется загрузка комплексного значения поворачивающего коэффициента W и одного отсчета В (вершины х1, x2, х5, x8).
С целью повышения быстродействия вычислений загрузка второго отсчета А во времени может быть совмещена с умножением или первым сложением (т. е. выполнена на втором или третьем такте). Параллельный умножитель КР1802ВР5 выполняет четыре операции умножения (второй такт). Результаты умножений записываются в процессорную секцию КМ1804ВС2, где программно выполняются остальные вычисления. Время вычислений распределяется по тактам следующим образом: первый такт — 0,8 мкс, второй — 0,6 мкс, третий и четвертый — 1,2 мкс, пятый — 1,2 мкс. Первое значение БО будет вычислено за 2,6 (мкс, следующие значения будут поступать с задержкой 1,2 мкс.
На рис. З.Э.в приведена структурная схема МП, обеспечивающего вычисление БО с максимально возможной скоростью (для заданного в табл. 3.5 набора МП). Высокая производительность вычислений достигнута максимальным их распараллеливанием и использованием аппаратных процессоров. За время одного цикла вычислений МПК КР1802 осуществляется выполнение каждого такта (см. рис. 3.8).
На рис. 3.9,г приведена структурная схема конвейерного МП БО без рас-лараллеливания вычислений. Длительность максимального такта равна временя последовательного вычисления шести операций сложения (0,9 мкс).
Для сравнительной оценки различных вариантов МП БО определим необходимую для их размещения площадь печатной платы. Разбиение печатной платы на основные поля и зоны показано на рис. 2.23. Размеры печатной платы могут быть определены из уравнений (2.5) и (2.6).